Proposals
In progress.
This the multi-page printable view of this section. Click here to print.
In progress.
This is a list of accepted proposals. This means proposal was accepted, but not yet implemented.
Owners:
Related Tickets:
Other docs:
TL;DR: As a mid-to-long term vision for the Monitoring Stack Operator we propose to rename MSO as OO (Observability Operator). With the name, we propose to establish OO as the open source, (single) cluster-side component for OpenShift observability needs. In conjunction with Observatorium / RHOBS - as the multi-cluster, multi-tenant, scalable observability backend component. OO is thought to manage different kinds of cluster-side monitoring, alerting, logging, and tracing (and potentially profiling) stack setups covering the needs of OpenShift variants like the client-side for the fully managed multi-cluster use cases to HyperShift and single node air gapped setups.
With the rise of new OpenShift variants with very different needs regarding observability, the desire for a consistent way of providing differently configured monitoring stacks grows. Examples:
The proposal is to combine all these (and more) use cases into one single (meta) operator (as recommended by the operator best practices) which can be configured with e.g. presets to instruct lower-level operators (like prometheus-operator, potentially Loki operator or Jaeger one) to deploy purpose-built monitoring stacks for different uses cases. This is similar to the original CMO concept but with much higher flexibility, and feature velocity in mind, thanks to not being tied to OpenShift Core versioning.
Additionally, supporting multiple different ways of deploying monitoring stacks (CMO as the standard OpenShift way, OO for managed services, something else for e.g. HyperShift or edge scenarios, …) is a burden for the team. Instead, eventually supporting only one way to deploy monitoring stacks - with OO - covering all these use cases makes it a lot simpler and far more consistent.
CMO is built for traditional self-operated single-cluster focused deployments of OpenShift. It intentionally lacks the flexibility for many other use cases (see above) in order to provide monitoring that is resilient against configuration drift. E.g. the reason for creating OO (MSO) in the first place - supporting managed service uses cases - can’t currently be covered by CMO. See the original MSO proposal for more details.
The results of this lack of flexibility can be readily observed: Red Hat teams have built their own solutions for their monitoring use cases, e.g. leveraging community operators or self-written deployments, with varying success, reliability and supportability.
Goals and use cases for the solution as proposed in How:
Collection of requirements and prioritization of use cases currently in progess (Q3 2022).
Owners:
Other docs:
TL;DR: I would like to propose to put all public documentation pieces related to the Monitoring Group (and not tied to a specific project) in the public GitHub repository called
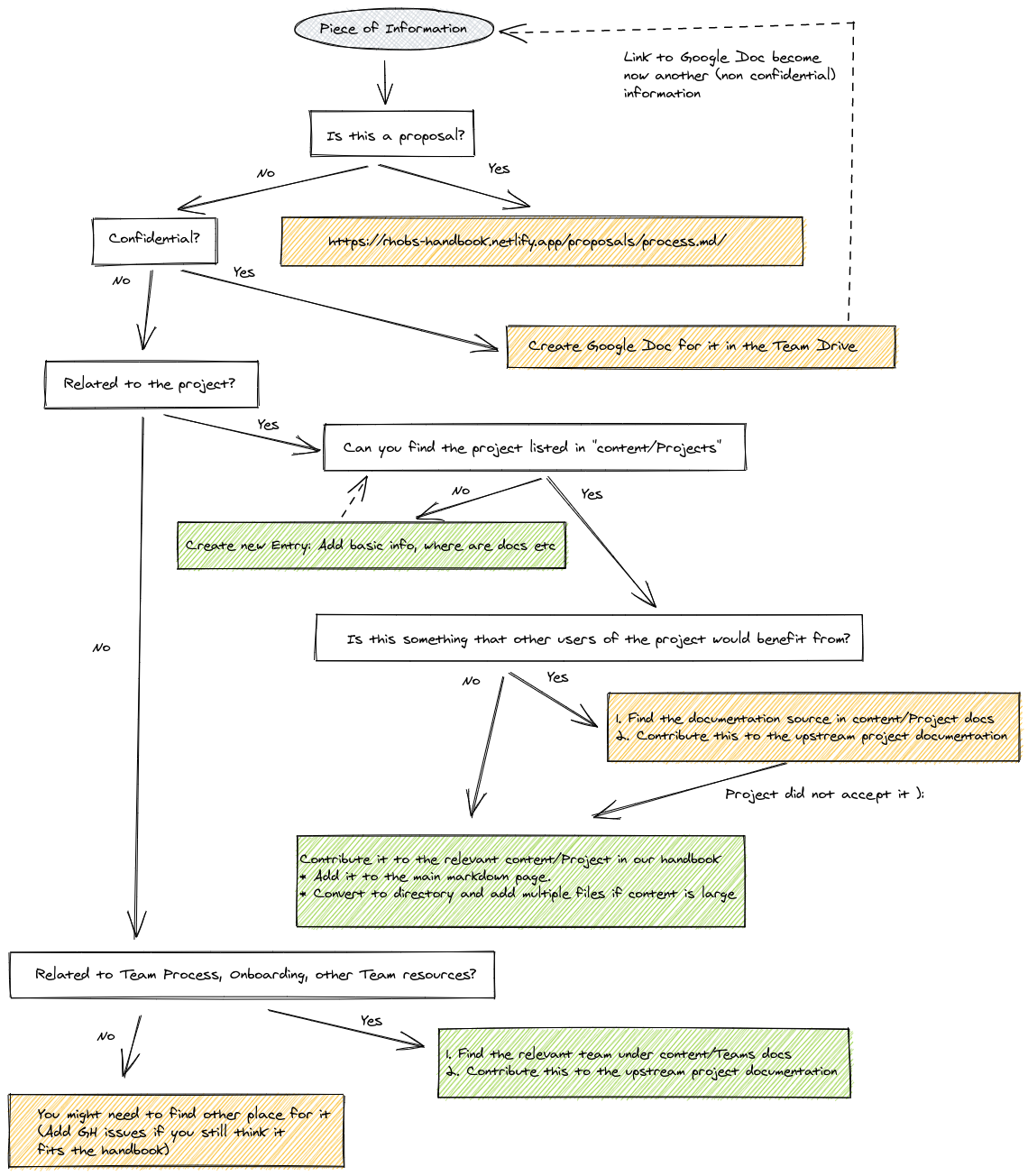
handbook. I propose to review all documents with a similar flow as code and put documents in the form of markdown files that can be read from both GitHub UI and automatically served on https://rhobs-handbook.netlify.app/ website.The diagram below shows what fits into this handbook and what should be distributed to the relevant upstream project (e.g developer documentation).
Demotivation is because our (Google Docs based) process tends to create the following obstacles:
All of those make people decide NOT to write documentation but rather schedule another meeting and repeat the same information repeatedly.
On a similar side, anyone looking for information about our teams' work, proposals or project is demotivated to look, find and read our documentation because it’s not consistent, not in a single place, hard to discover or not completed.
Goals and use cases for the solution as proposed in How:
NOTE: We would love to host Logging and Tracing Teams if they choose to follow our process, but we don’t want to enforce it. We are happy to extend this handbook from Monitoring Group handbook to Observability Group, but it has to grow organically (if Logging, Tracing team will see the value joining us here).
The currently planned audience for proposed documentation content is following (in importance order):
Markdown e.g. Asciidoc.The idea is simple:
Let’s make sure we maintain the process of adding/editing documentation as easy and rewarding as possible. This will increase the chances team members will document things more often and adopt this as a habit. Produced content will be more likely complete and up-to-date, increasing the chances it will be helpful to our audience, which will reduce the meeting burden. This will make writing docs much more rewarding, which creates a positive loop.
I propose to use git repository handbook to put all related team documentation pieces there. Furthermore, I suggest reviewing all documents with a similar flow as code and placing information in the form of markdown files that can be read from both GitHub UI and automatically served on https://rhobs-handbook.netlify.app/ website.
Pros:
Cons:
The idea of a handbook is not new. Many organizations do this e.g GitLab.
NOTE: The website style might be not perfect (https://rhobs-handbook.netlify.app/). Feel free to propose issues, fixes to the overall look and readability!
If you want to add or edit markdown documentation, refer to our technical guide.
Pros:
Cons:
Pros:
Cons:
This is a list of implemented proposals.
Owners::
Other docs:
TL;DR: We would like to propose an improved, official proposal process for Monitoring Group that clearly states when, where and how to create proposal/enhancement/design documents.
More extensive architectural, process, or feature decisions are hard to explain, understand and discuss. It takes a lot of time to describe the idea, to motivate interested parties to review it, give feedback and approve. That’s why it is essential to streamline the proposal process.
Given that we work in highly distributed teams and work with multiple communities, we need to allow asynchronous discussions. This means it’s essential to structure the talks into shared documents. Persisting in those decisions, once approved or rejected, is equally important, allowing us to understand previous motivations.
There is a common saying "I've just been around long enough to know where the bodies are buried". We want to ensure the team related knowledge is accessible to everyone, every day, no matter if the team member is new or part of the team for ten years.
Currently, the Observability Platform team have the process defined here (internal), whereas the In-Cluster part were not defining any official process (as per here (internal)).
In practice, both teams had somehow similar flow:
It served us well, but it had the following issues (really similar to ones stated in handbook proposal):
Goals and use cases for the solution as proposed in How:
We want to propose an improved, official proposal process for Monitoring Group that clearly states when, where and how to create proposal/enhancement/design documents.
Everything starts with a problem statement. It might be a missing functionality, confusing existing functionality or broken one. It might be an annoying process, performance or security issue (or potential one).
As defined in handbook proposal, our Handbook should tell you that Handbook is meant to be an index for our team resources and a linking point to other distributed projects we maintain or contribute to.
First, we need to identify if the idea we have is something we can contribute to an upstream project, or it does not fit anywhere else, so we can leverage the Handbok Proposal directory and the process. See the below algorithm to find it out:
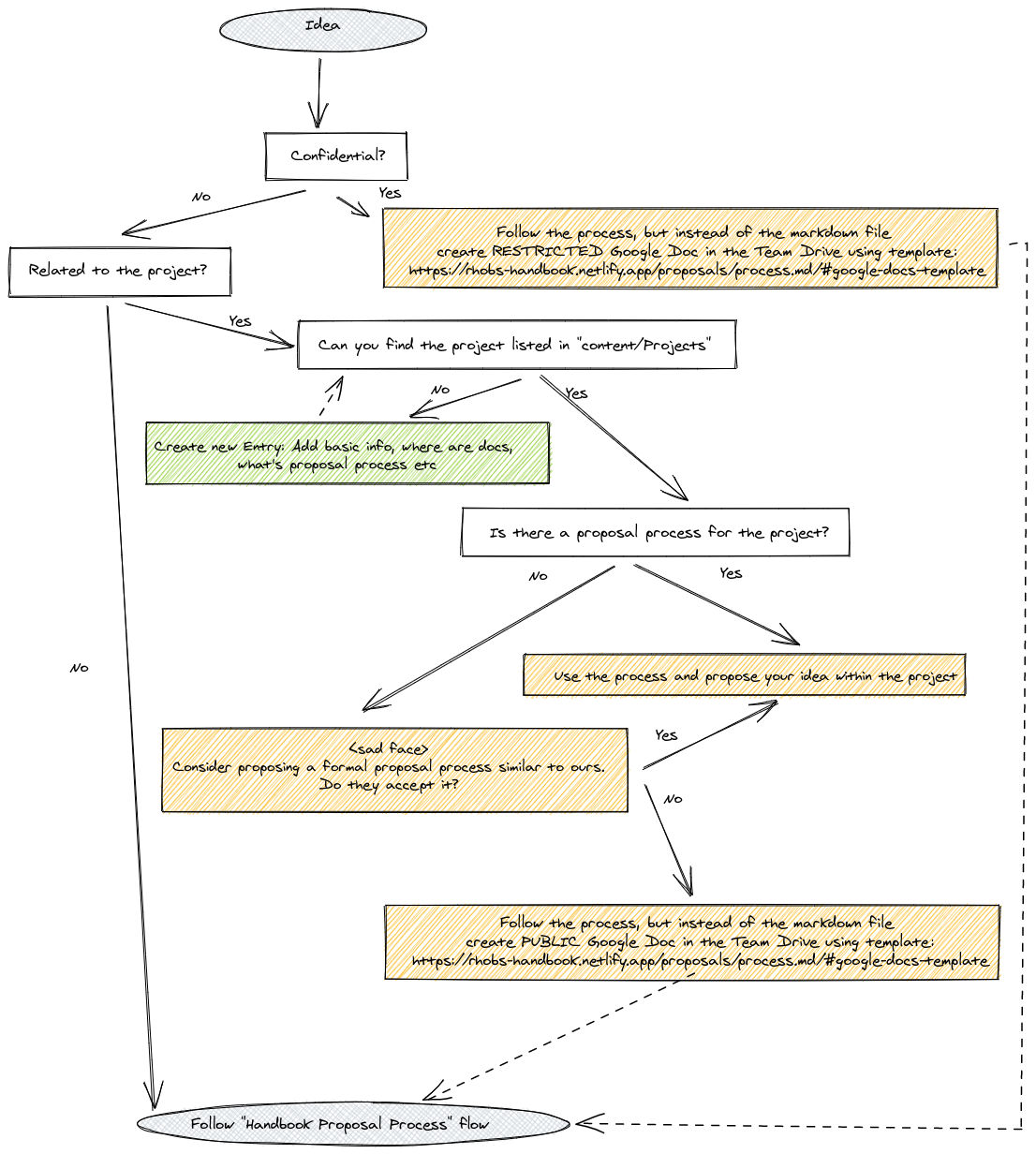
Internal Team Drive for Public and Confidential Proposals
If there is no problem, there is no need for changing anything, no need for a proposal. This might feel trivial, but we should first ask ourselves this question before even thinking about writing a proposal.
It takes time to propose an idea, find consensus and implement more significant concepts, so let’s not waste time before it’s worth it. But, unfortunately, even good ideas sometimes have to wait for a good moment to discuss them.
Let’s assume the idea sounds interesting to you; what to do next, where to propose it? How to review it? Follow the algorithm below:
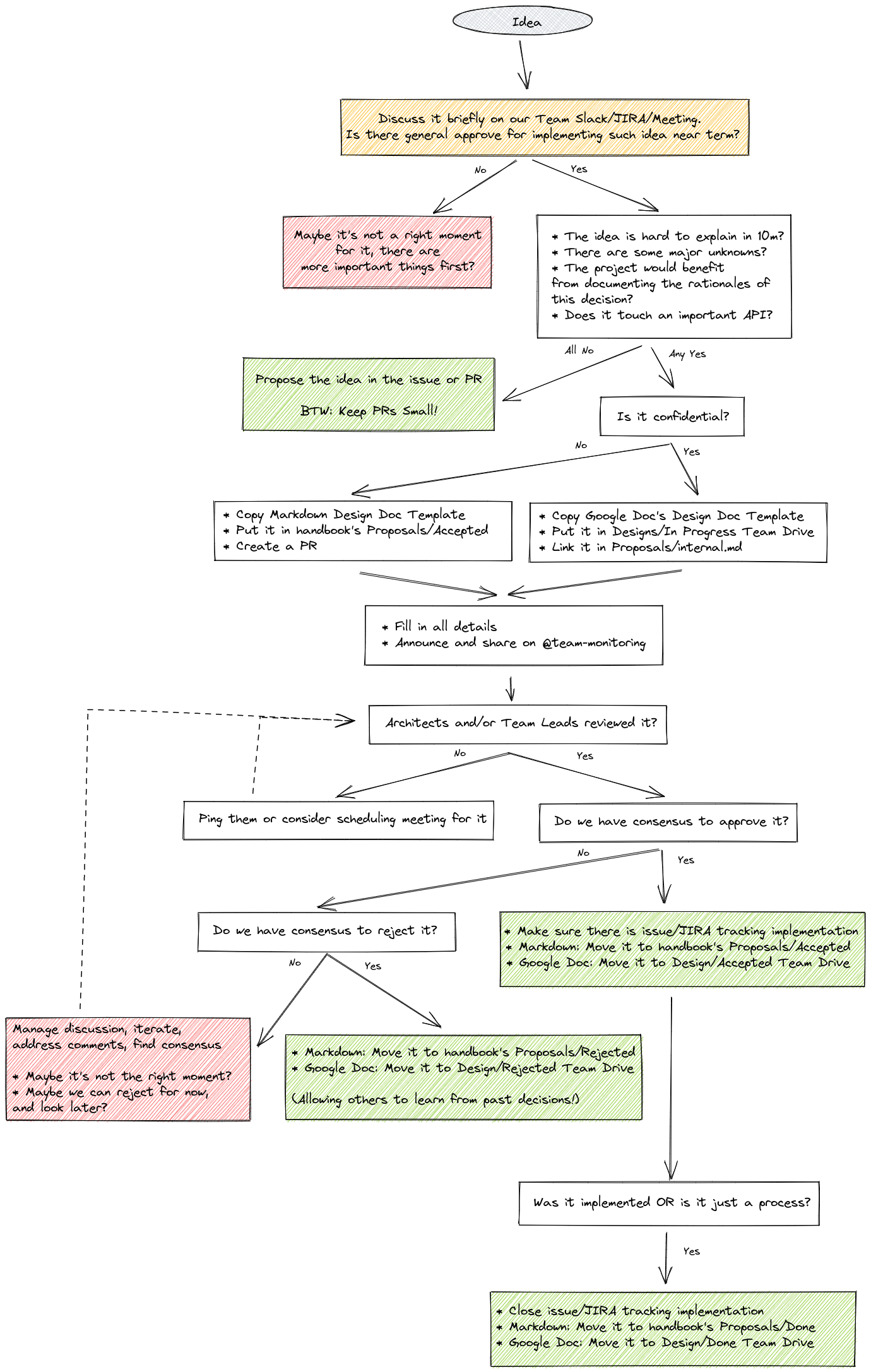
Note: It’s totally ok to reject a proposal if a team member feels the idea is wrong. It’s better to explicitly oppose it than to ignore it and leave it in limbo.
NOTE: We would love to host Logging and Tracing Teams if they choose to follow our process, but we don’t want to enforce it. We are happy to extend this process from the Monitoring Group handbook to Observability Group. Still, it has to grow organically (if the Logging, Tracing team will see the value of joining us here).
As you see on the above algorithm, if the content relates to any upstream project, it should be proposed, reviewed and potentially implemented together with the community. This does not mean that you cannot involve other team members towards this effort. Share the proposal with team members, even if they are not part of maintainer’s team on a given project, any feedback, and voice are useful and can help to move idea further.
Similar to proposals that touch our team only, despite mentioning mandatory approval process from leads, anyone can give feedback! Our process is in fact very similar to Hashicorp’s RFC process:
Once you’ve written the first draft of an RFC, share it with your team. They’re likely to have the most context on your proposal and its potential impacts, so most of your feedback will probably come at this stage. Any team member can comment on and approve an RFC, but you need explicit approval only from the appropriate team leads in order to move forward. Once the RFC is approved and shared with stakeholders, you can start implementing the solution. For major projects, also share the RFC to the company-wide email list. While most members of the mailing list will just read the email rather than the full RFC, sending it to the list gives visibility into major decisions being made across the company.
Overall, we want to bring a culture where design docs will be reviewed in certain amount of time and authors (team members) will be given feedback. This, coupled with recognizing the work and being able to add it to your list of achievements (even if proposal was rejected), should bring more motivation for people and teams to assess ideas in structure, sustainable way.
Pros:
Cons:
As defined in handbook proposal, our Handbook should tell you that Handbook is meant to be an index for our team resources and a linking point to other distributed projects we maintain or contribute to.
First, we need to identify if the idea we have is something we can contribute to an upstream project, or it does not fit anywhere else, so we can leverage the Handbok Proposal directory and the process. See the below algorithm to find it out:

Internal Team Drive for Public and Confidential Proposals
If there is no problem, there is no need for changing anything, no need for a proposal. This might feel trivial, but we should first ask ourselves this question before even thinking about writing a proposal.
It takes time to propose an idea, find consensus and implement more significant concepts, so let’s not waste time before it’s worth it. But, unfortunately, even good ideas sometimes have to wait for a good moment to discuss them.
Let’s assume the idea sounds interesting to you; what to do next, where to propose it? How to review it? Follow the algorithm below:

Note: It’s totally ok to reject a proposal if a team member feels the idea is wrong. It’s better to explicitly oppose it than to ignore it and leave it in limbo.
NOTE: We would love to host Logging and Tracing Teams if they choose to follow our process, but we don’t want to enforce it. We are happy to extend this process from the Monitoring Group handbook to Observability Group. Still, it has to grow organically (if the Logging, Tracing team will see the value of joining us here).
As you see on the above algorithm, if the content relates to any upstream project, it should be proposed, reviewed and potentially implemented together with the community. This does not mean that you can involve other team members towards this effort. Share the proposal with team members, even if they are not part of maintainer’s team on a given project, any feedback, and voice are useful and can help to move idea further.
Similar to proposals that touch our team only, despite mentioning mandatory approval process from leads, anyone can give feedback! Our process is in fact very similar to Hashicorp’s RFC process:
Once you’ve written the first draft of an RFC, share it with your team. They’re likely to have the most context on your proposal and its potential impacts, so most of your feedback will probably come at this stage. Any team member can comment on and approve an RFC, but you need explicit approval only from the appropriate team leads in order to move forward. Once the RFC is approved and shared with stakeholders, you can start implementing the solution. For major projects, also share the RFC to the company-wide email list. While most members of the mailing list will just read the email rather than the full RFC, sending it to the list gives visibility into major decisions being made across the company.
Open Source Design Doc Template.
Owners:
<@author: single champion for the moment of writing>Related Tickets:
<JIRA, GH Issues>Other docs:
<Links…>TL;DR: Give here a short summary of what this document is proposing and what components it is touching. Outline rough idea of proposer’s view on proposed changes.
For example: This design doc is proposing a consistent design template for “example.com” organization.
Put here a motivation behind the change proposed by this design document, give context.
For example: It’s important to clearly explain the reasons behind certain design decisions in order to have a consensus between team members, as well as external stakeholders. Such a design document can also be used as a reference and knowledge-sharing purposes. That’s why we are proposing a consistent style of the design document that will be used for future designs.
What specific problems are we hitting with the current solution? Why it’s not enough?
For example, We were missing a consistent design doc template, so each team/person was creating their own. Because of inconsistencies, those documents were harder to understand, and it was easy to miss important sections. This was causing certain engineering time to be wasted.
Goals and use cases for the solution as proposed in How:
If not clear, the target audience that this change relates to.
Explain the full overview of the proposed solution. Some guidelines:
The section stating potential alternatives. Highlight the objections reader should have towards your proposal as they read it. Tell them why you still think you should take this path [ref]
The tasks to do in order to migrate to the new idea.
This is a list of rejected proposals.
NOTE: This does not mean we can return to them and accept!