Accepted
Accepted
This is a list of accepted proposals. This means proposal was accepted, but not yet implemented.
Internal Accepted Proposals
1 - ## Evolution of the Observability Operator (fka MSO)
Evolution of the Observability Operator (fka MSO)
-
Owners:
-
Related Tickets:
-
Other docs:
TL;DR: As a mid-to-long term vision for the Monitoring Stack Operator we propose to rename MSO as OO (Observability Operator). With the name, we propose to establish OO as the open source, (single) cluster-side component for OpenShift observability needs. In conjunction with Observatorium / RHOBS - as the multi-cluster, multi-tenant, scalable observability backend component. OO is thought to manage different kinds of cluster-side monitoring, alerting, logging, and tracing (and potentially profiling) stack setups covering the needs of OpenShift variants like the client-side for the fully managed multi-cluster use cases to HyperShift and single node air gapped setups.
Why
With the rise of new OpenShift variants with very different needs regarding observability, the desire for a consistent way of providing differently configured monitoring stacks grows. Examples:
- Traditional single-cluster on-prem OpenShift deployments need a self-contained monitoring stack where all components (scraping, storage, visualization, alerting, log collection) run on the same cluster. This is the kind of setup Cluster Monitoring Operator was designed for.
- Multi-cluster deployments need a central (aggregated, federated) view on metrics, logs and alerts. Certain components of the stack don’t run on the workload clusters but in some central infrastructure.
- Resource-constraint deployments need a stripped down version of the monitoring stack, e.g. only forwarding signals to a central infrastructure or disabling certain parts of the stack completely.
- Mixed deployments (e.g. OpenShift + OpenStack) are conceptually very similar to the multi-cluster use case, also needing a central pane of glass for observability signals.
- Special purpose deployments (e.g. OpenShift Data Foundation) have special requirements when it comes to monitoring, that are tricky to align with the existing CMO setup.
- Looking at eventually correlating different observability signals also the cluster-side stack would potentially benefit from a holistic approach for deploying monitoring, logging and tracing components and configuring them in the right way to work together.
- Managed service deployments need a multi tenancy capable way of deploying many similarly built monitoring stacks to a single cluster. This is the short-term focus for OO.
The proposal is to combine all these (and more) use cases into one single (meta) operator (as recommended by the operator best practices) which can be configured with e.g. presets to instruct lower-level operators (like prometheus-operator, potentially Loki operator or Jaeger one) to deploy purpose-built monitoring stacks for different uses cases. This is similar to the original CMO concept but with much higher flexibility, and feature velocity in mind, thanks to not being tied to OpenShift Core versioning.
Additionally, supporting multiple different ways of deploying monitoring stacks (CMO as the standard OpenShift way, OO for managed services, something else for e.g. HyperShift or edge scenarios, …) is a burden for the team. Instead, eventually supporting only one way to deploy monitoring stacks - with OO - covering all these use cases makes it a lot simpler and far more consistent.
Pitfalls of the current solution
CMO is built for traditional self-operated single-cluster focused deployments of OpenShift. It intentionally lacks the flexibility for many other use cases (see above) in order to provide monitoring that is resilient against configuration drift. E.g. the reason for creating OO (MSO) in the first place - supporting managed service uses cases - can’t currently be covered by CMO. See the original MSO proposal for more details.
The results of this lack of flexibility can be readily observed: Red Hat teams have built their own solutions for their monitoring use cases, e.g. leveraging community operators or self-written deployments, with varying success, reliability and supportability.
Goals
Goals and use cases for the solution as proposed in How:
- Widen the scope of OO to cover additional use cases besides managed services.
- Replace existing ways of deploying monitoring stacks across Red Hat products with OO.
- Focus on OpenShift use cases primarily but don’t exclude vanilla Kubernetes as a possible target.
- Create an API that easily allows common configuration across observability signals.
Non-Goals
- Create a multi-cluster capable observability operator.
How
- Define use cases to be covered in detail.
- Prioritize use cases and add needed features one by one.
Alternatives
- Tackle each monitoring use case across Red Hat products one by one and build a custom solution for them. This would lead to many different (but potentially simpler) implementations which need to be supported.
- Develop signal specific operators that can handle the required use cases. This would likely require an API between those operators to apply common configuration.
Action Plan
Collection of requirements and prioritization of use cases currently in progess (Q3 2022).
2 - 2021-06: Handbook
2021-06: Handbook
TL;DR: I would like to propose to put all public documentation pieces related to the Monitoring Group (and not tied to a specific project) in the public GitHub repository called handbook. I propose to review all documents with a similar flow as code and put documents in the form of markdown files that can be read from both GitHub UI and automatically served on https://rhobs-handbook.netlify.app/ website.
The diagram below shows what fits into this handbook and what should be distributed to the relevant upstream project (e.g developer documentation).
Why
Documentation is essential
- Without good team processes documentation, collaboration within the team can be challenging. Members have to figure out what to do on their own, or tribal knowledge has to be propagated. Surprises and conflicts can arise. On-boarding new team members are hard. It’s vital given that our Red Hat teams are distributed over the world and working remotely.
- Additionally, it’s hard for any internal or external team to discover how to reach us or escalate without noise.
- Without a good team subject matter overview, it’s hard to wrap your head around the number of projects we participate in. In addition, each team member is proficient in a different area, and we miss some “index” overview of where to navigate for various project aspects (documentation, contributing, proposals, chats).
- Even if documentation is created, it risks being placed in the wrong place.
- Without a place for written design proposals (those in progress, those accepted and rejected), the team risks repeating iterating over the same ideas or challenging old ideas already researched.
- Without good operational or configuration knowledge, we keep asking the same question about, e.g. how to rollout service X or contribute to X etc.
Despite strong incentives, writing documentation has proven to be of one the most unwanted task among engineers
Demotivation is because our (Google Docs based) process tends to create the following obstacles:
- There are too many side decisions to make, e.g. where to put this documentation, what format to use, how long, how to be on-topic, are we sure this information is not recorded somewhere else? Every, even small decision takes our energy and have the risk of procrastination.
- There is no review process, so it’s hard to maintain a high quality of those documents.
- Created documentation is tough to consume and discover.
- Because docs are hard to discover, the documentation tends to be often duplicated, has gaps, or is obsolete.
- Documents used to be private, which brings extra demotivation. Some of the information is useful for the public audience. Some of this could be useful for external contributors. It’s hard to reuse such private docs without recreating them.
All of those make people decide NOT to write documentation but rather schedule another meeting and repeat the same information repeatedly.
On a similar side, anyone looking for information about our teams' work, proposals or project is demotivated to look, find and read our documentation because it’s not consistent, not in a single place, hard to discover or not completed.
Pitfalls of the current solution
- It mainly exists in Google Docs, which has the following issues:
- Not everything is in our Team drive, there are docs not owned by us, created adhoc.
- It’s painful to organize them well e.g in directories, since it’s so easy so copy, create one.
- Even if it’s organized well, it’s not easily discoverable.
- Existing Google doc-based documents are hard to consume. The formatting is widely different. Naming is inconsistent.
- Document creation is rarely actionable. There is no review process, so the effort of creating a relevant document might be wasted, as the document is lost. This also leads to docs being in the half-completed state, demotivating readers to look at it.
- It’s hard to track previous discussions around docs, who approved them (e.g. proposals).
- It’s not public, and it’s hard to share best practices with other external and internal teams.
Goals
Goals and use cases for the solution as proposed in How:
- Single source of truth for Monitoring Group Team docs like processes, overviews, runbooks, links for internal content.
- Have a consistent documentation format that is readable and understandable.
- Searchable and easily discoverable.
- Process of adding documents should be easy and consistent.
- Automation and normal review process should be in place to ensure high quality (e.g. link checking).
- Allow public collaboration on processes and other docs.
NOTE: We would love to host Logging and Tracing Teams if they choose to follow our process, but we don’t want to enforce it. We are happy to extend this handbook from Monitoring Group handbook to Observability Group, but it has to grow organically (if Logging, Tracing team will see the value joining us here).
Audience
The currently planned audience for proposed documentation content is following (in importance order):
- Monitoring Group Team Members.
- External Teams at Red Hat.
- Teams outside Red Hat, contributors to our projects, potential future hires, people interested in best practices, team processes etc.
Non-Goals
- Support other formats than
Markdown e.g. Asciidoc.
- Replace official project or product documentation.
- Precise design proposal process (it will come in a separate proposal).
- Sharing Team Statuses, we use JIRA and GH issues for that.
How
The idea is simple:
Let’s make sure we maintain the process of adding/editing documentation as easy and rewarding as possible. This will increase the chances team members will document things more often and adopt this as a habit. Produced content will be more likely complete and up-to-date, increasing the chances it will be helpful to our audience, which will reduce the meeting burden. This will make writing docs much more rewarding, which creates a positive loop.
I propose to use git repository handbook to put all related team documentation pieces there. Furthermore, I suggest reviewing all documents with a similar flow as code and placing information in the form of markdown files that can be read from both GitHub UI and automatically served on https://rhobs-handbook.netlify.app/ website.
Pros:
- Matches our goals.
- Sharing by default.
- Low barriers to write documents in a consistent format, low barrier to consume it.
- Ensures high quality with local CI and review process.
Cons:
- Some website maintenance is needed, but we use the same and heavily automated flow in Prometheus-operator, Thanos, Observatorium websites etc.
The idea of a handbook is not new. Many organizations do this e.g GitLab.
NOTE: The website style might be not perfect (https://rhobs-handbook.netlify.app/). Feel free to propose issues, fixes to the overall look and readability!
Flow of Adding/Consuming Documentation to Handbook
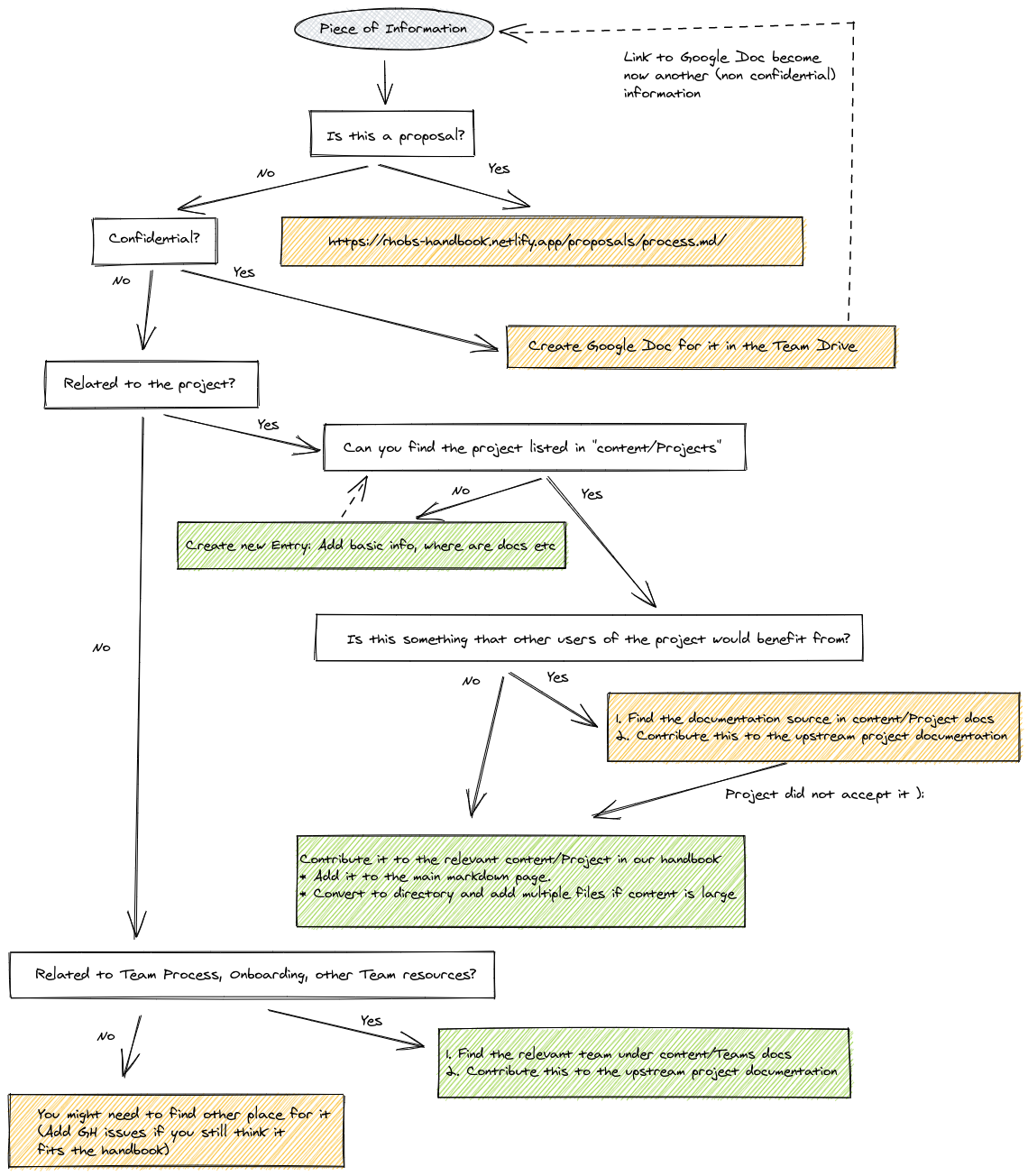
If you want to add or edit markdown documentation, refer to our technical guide.
Alternatives
- Organize Team Google Drive with all Google docs we have.
Pros:
- Great for initial collaboration
Cons:
- Inconsistent format
- Hard to track approvers
- Never know when the doc is “completed.”
- Hard to maintain over time
- Hard to share and reuse outside
- Create Red Hat scoped only, a private handbook.
Pros:
- No worry if we share something internal?
Cons:
- We don’t have many internal things we don’t want to share at the current moment. All our projects and products are public.
- Sharing means we have to duplicate the information, copy it in multiple places.
- Harder to share with external teams
- We can’t use open source tools, CIs etc.
Action Plan