Red Hat Observability Service
5 minute read
Red Hat Observability Service
Previous Documents:
What
Red Hat Observability Service (RHOBS) is a managed, centralized, multi-tenant, scalable backend for observability data. Functionally it is an internal deployment of Observatorium project. RHOBS is designed to allow ingesting, storing and consuming (visualisations, import, alerting, correlation) observability signals like metrics, logging and tracing.
This document provides the basic overview of the RHOBS service. If you want to learn about RHOBS architecture, look for Observatorium default deployment and its design.
Background
With the amount of managed Openshift clusters, for Red Hat’s own use as well as for customers, there is a strong need to improve the observability of those clusters and of their workloads to the multi-cluster level. Moreover, with the “clusters as cattle” concept, more automation and complexity there is a strong need for a uniform service gathering observability data including metrics, logs, traces, etc into a remote, centralized location for multi-cluster aggregation and long term storage.
This need is due to many factors:
- Managing applications running on more than one cluster, which is a default nowadays (cluster as a cattle),
- Need to offload data and observability services from edge cluster to reduce complexity and cost of edge cluster (e.g remote health capabilities).
- Allow offloading teams from maintaining their own observability service.
It’s worth noting that there is also a significant benefit to collecting and using multiple signals within one system:
- Correlating signals and creating a smooth and richer debugging UX.
- Sharing common functionality, like rate limiting, retries, auth, etc, which allows a consistent integration and management experience for users.
The Openshift Monitoring Team began preparing for this shift in 2018 with the Telemeter Service. In particular, while creating the second version of the Telemeter Service, we put effort into developing and contributing to open source systems and integration to design “Observatorium”: a multi-signal, multi-tenant system that can be operated easily and cheaply as a Service either by Red Hat or on-premise. After extending the scope of the RHOBS, Telemeter become the first “tenant” of the RHOBS.
In Summer 2020, the Monitoring Team together with the OpenShift Logging Team added a logging signal to “Observatorium” and started to manage it for internal teams as the RHOBS.
Current Usage
RHOBS is running in production and has already been offered to various internal teams, with more extensions and expansions coming in the near future.
- There is currently no plan to offer RHOBS to external customers.
- However anyone is welcome to deploy and manage an RHOBS-like-service on their own using Observatorium.
Usage (state as of 2021.07.01):
The metric usage is visualised in the following diagram:
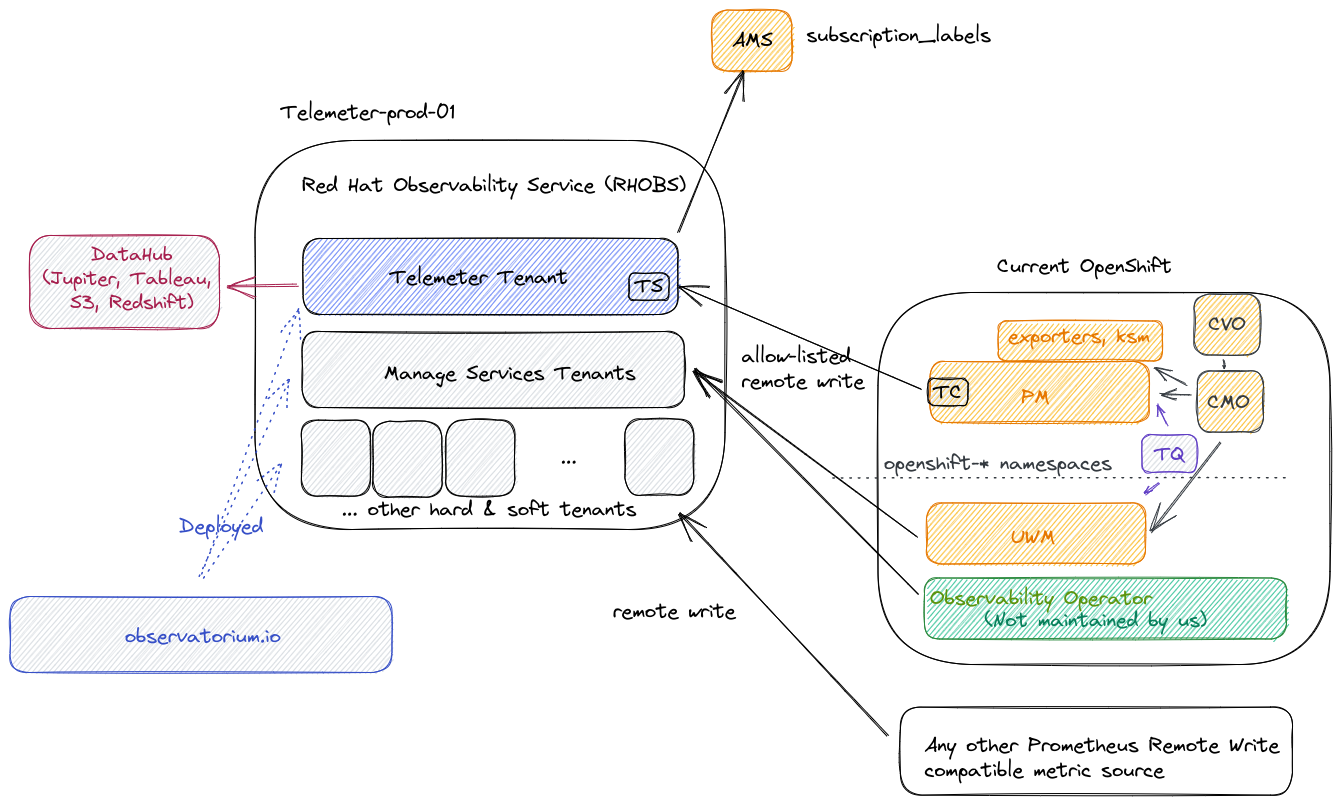
RHOBS is functionally separated into two main usage categories:
- Since 2018 we run Telemeter tenant for metric signal (hard tenancy,
telemeter-prod-01cluster). See telemeter for details. - Since 2021 we ingest metrics for selected Managed Services as soft tenants in an independent deployment (separate soft tenant,
telemeter-prod-01cluster). See MST for details.
Other signals:
- Since 2020 we ingest logs for the DPTP team (hard tenancy,
telemeter-prod-01cluster).
Hard vs Soft tenancy: In principle hard tenancy means that in order to run system for multiple tenants you run each stack (can be still in single cluster, yet isolated through e.g namespaces) for each tenant. Soft tenancy means that we reuse same endpoint and services to handle tenant APIs. For tenant both tenancy models should be invisible. We chose Telemeter to be deployed in different stack, because of Telemeter critical nature and different functional purpose that makes Telemeter performance characteristics bit different to normal monitoring setup (more analytics-driven cardinality).
Owners
RHOBS was initially designed by Monitoring Group and its metric signal is managed and supported by Monitoring Group team (OpenShift organization) together with AppSRE team (Service Delivery organization).
Other signals are managed by others team (each together with AppSRE help):
- Logging signal: OpenShift Logging Team
- Tracing signal: OpenShift Tracing Team
Telemeter part client side is maintained by In-cluster Monitoring team, but managed by corresponding client cluster owner.
Metric Label Restrictions
There is small set of reserved label name that are reserved on RHOBS side. If remote write request contains series with those labels, they will be overridden (not honoured).
Restricted labels:
tenant_id: Internal tenant ID in form of UUID that is injected to all series in various placed and constructed from tenant authorization (HTTP header).receive: Special label used internally.replicaandrule_replica: Special label used internally to replicate receive and rule data for reliability.
Special labels:
prometheus_replica: Use this label for Agent/Prometheus unique scraper ID if you scrape and push from multiple of replicas scraping the same data. RHOBS is configured to deduplicate metrics based on this.
Recommended labels:
_idfor cluster ID (in form of lowercase UUID) is the common way of identifying clusters.prometheusis a name of Prometheus (or any other scraper) that was used to collect metrics.jobis scrape job name that is usually dynamically set to abstracted service name representing microservice (usually deployment/statefulset name)namespaceis Kubernetes namespace. Useful to make sure identify same microservices across namespaces.- For more “version” based granularit (warning - every pod rollout creates new time series).
podis a pod nameinstanceis an IP:port (useful when pod has sidecars)imageis image name and tag.
Support
For support see:
Last modified January 23, 2026