Telemetry (Telemeter)
2 minute read
Telemetry (Telemeter)
For RHOBS Overview see this document
Telemeter is the metrics-only hard tenant of the RHOBS service designed as a centralized OpenShift Telemetry pipeline for OpenShift Container Platform. It is an essential part of gathering real-time telemetry for remote health monitoring, automation and billing purposes.
- OpenShift Documentation about the Telemetry service.
- Internal documentation for interacting with the Telemetry data.
Product Managers
- Roger Floren
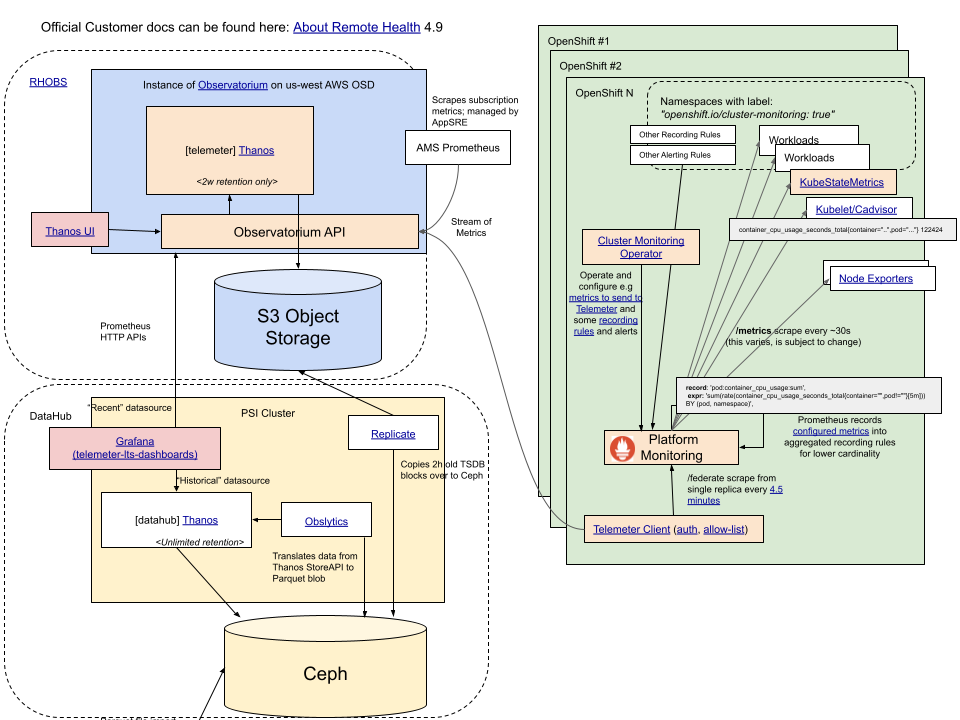
Big Picture Overview
Support
To escalate issues use, depending on issue type:
- For questions related to the service or kind of data it ingests, use
telemetry-sme@redhat.com(internal) mail address. For quick questions you can try to use #forum-telemetry on CoreOS Slack. - For functional bugs or feature requests use Bugzilla, with Product:
Openshift Container PlatformandTelemetercomponent (example bug). You can additionally notify us about a new bug on#forum-telemetryon CoreOS Slack. - For functional bugs or feature requests for historical storage (Data Hub), use the PNT Jira project.
For the managing team: See our internal agreement document.
Escalations
For urgent escalation use:
- For Telemeter Service Unavailability:
@app-sre-icand@observatorium-oncallon CoreOS Slack. - For Historical Data (DataHub) Service Unavailability:
@data-hub-icon CoreOS Slack.
Service Level Agreement
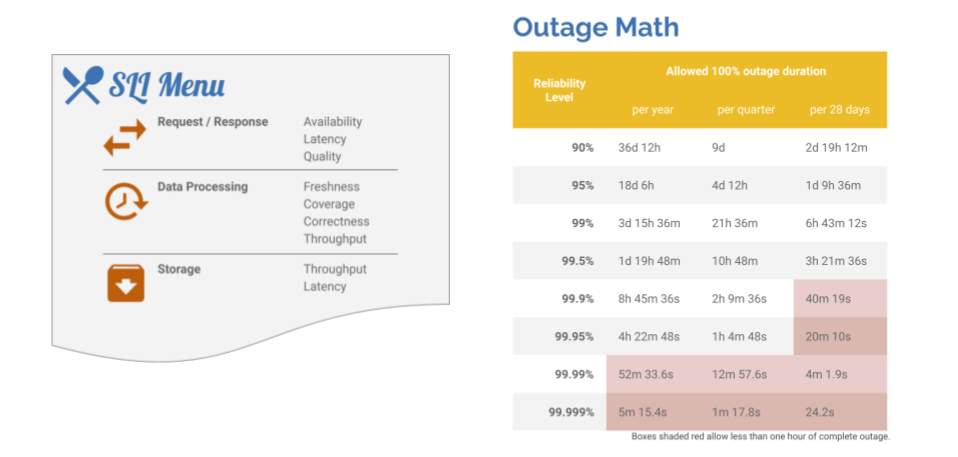
RHOBS has currently established the following default Service Level Objectives. This is based on the infrastructure dependencies we have listed here (internal).
Previous docs (internal):
Metrics SLIs
| API | SLI Type | SLI Spec | Period | SLI Implementation | Dashboard |
|---|---|---|---|---|---|
/write |
Availability | The % of successful (non 5xx) requests | 28d | Metrics from Observatorium API | Dashboard |
/write |
Latency | The % of requests under X latency | 28d | Metrics from Observatorium API | Dashboard |
Read Metrics TBD.
Agreements:
NOTE: No entry for your case (e.g. dev/staging) means zero formal guarantees.
| SLI | Date of Agreement | Tier | SLO | Notes |
|---|---|---|---|---|
/write Availability |
2020/2019 | Internal (default) | 99% success rate for incoming requests | This depends on SSO RedHat com SLO (98.5%). In worst case (everyone needs to refresh token) we have below 98.5%, in the avg case with caching being 5m (we cannot change it) ~99% (assuming we can preserve 5m) |
/write Latency |
2020/2019 | Internal (default) | 95% of requests < 250ms, 99% of requests < 1s |
Write Limits
Within our SLO, the write request must match following criteria to be considered valid:
- Valid remote write requests using official remote write protocol (See conformance test)
- Valid credentials: (explanation TBD(https://github.com/rhobs/handbook/issues/24))
- Max samples: TBD(https://github.com/rhobs/handbook/issues/24)
- Max series: TBD(https://github.com/rhobs/handbook/issues/24)
- Rate limit: TBD(https://github.com/rhobs/handbook/issues/24)
TODO: Provide example tune-ed client Prometheus configurations for remote write